My colleagues Ajay Joshi & Deepak Shah were discussing https://jsontoon.com/ which converts JSON to TOON format which is supposedly a more compact format with less token usage on LLMs.
TOON: Token-Oriented Object Notation is a compact, human-readable serialization format designed for passing structured data to Large Language Models with significantly reduced token usage. It's intended for LLM input as a lossless, drop-in representation of JSON data. Website: https://github.com/toon-format/toon
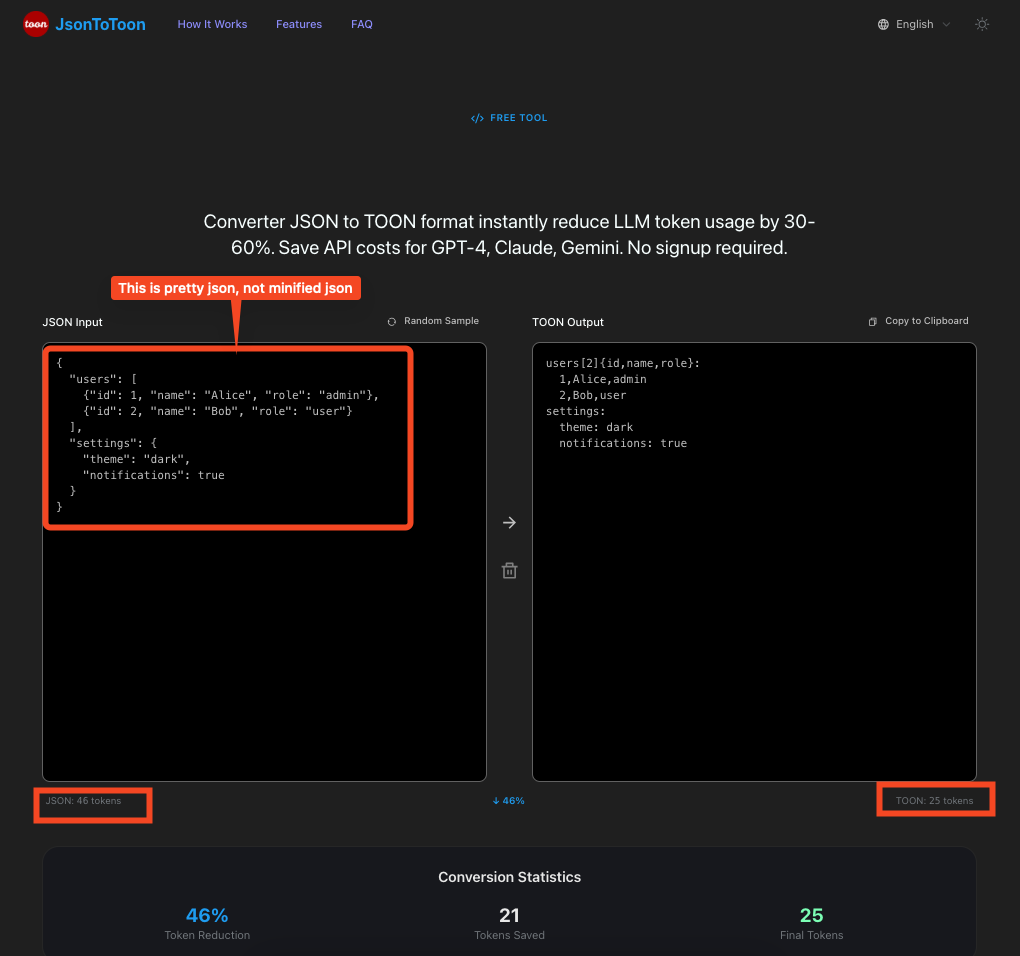
The example on https://jsontoon.com/ website compares TOON to "pretty json" (but not to minified json):
But I was curious to compare: if toon format is consistently using lesser tokens than "minified json". So I searched reddit:
Disclaimer for this approach: Make sure your original JSONs have enough self‑contained context. When you shorten keys, like if main_character = mc, you’re removing semantic hints [for LLM model]. To keep things clear for the LLM, your original JSON should include enough surrounding info or a parent scope so it’s obvious what domain you’re in.
I think that we can solve this with a Taxanomy.md added in system prompt which simply has key value pairs e.g. mc:main_character;n=name;t=traits....
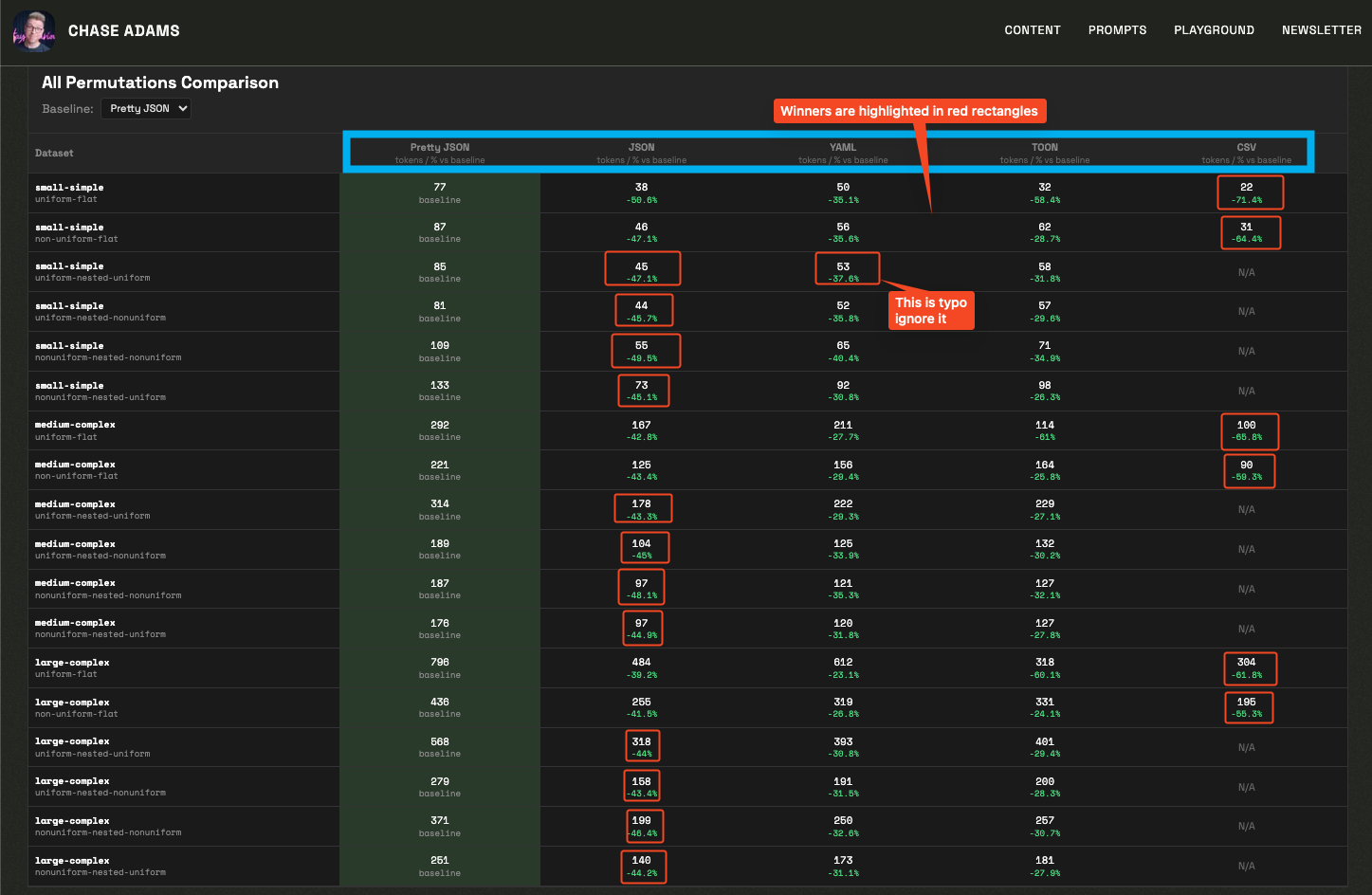
When a CSV lossless representation of data exists, CSV is always most token efficient
If a CSV lossless representation doesn't exists, minified json is always most token efficient.
So with a cursory read / limited understanding of this table seems to suggest that CSV/minifiedJSON seems better, but then TOON's readme has benchmarks section (that looks at both token usage as well as accuracy) and paints a different story: https://github.com/toon-format/toon?tab=readme-ov-file#benchmarks
This isn't the end of it. I intend to dive deeper into this, but got a busy week ahead. I will update this post if and when I get time to explore more about this topic.